 SpatialGrounding
SpatialGrounding
Abstract
We present SpatialGrounding, a novel multi-modal framework designed to ground high-level semantic concepts within geometrically precise 3D reconstructions of indoor environments, specifically for mobile robot spatial understanding. Our approach addresses critical challenges by fusing heterogeneous sensor data, integrating LDS SLAM 2D pose priors and 2D occupancy maps with deep learning-based visual matching from monocular image sequences.
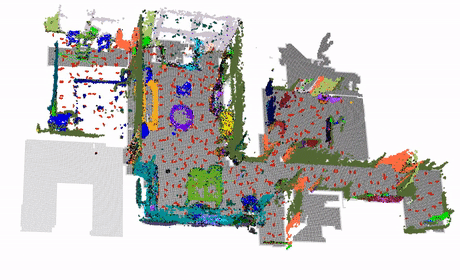
The system's core establishes a high-fidelity geometric foundation by leveraging pose priors from SLAM to solve scale ambiguity and enforce global consistency. An intelligent image pair selection strategy, guided by the robot's 2D occupancy map, significantly reduces computational overhead. This spatially-constrained data is processed using MASt3R for robust feature matching and GLOMAP for global optimization. Subsequently, the framework achieves semantic grounding by employing FC-CLIP to lift 2D visual cues into dense 3D semantic fields. This yields key structured outputs, including high-density semantic point clouds and semantically-enriched Bird's-Eye View (BEV) maps that delineate the architectural layout.
Key contributions include: (1) A unified framework that fuses LDS SLAM 2D pose priors with visual reconstruction, solving scale ambiguity and improving geometric accuracy through spatial constraints from robot navigation data. (2) An intelligent image pair selection strategy guided by 2D occupancy maps, which significantly reduces computational overhead while maintaining reconstruction quality. (3) A pipeline from raw sensor data to semantic 3D understanding, incorporating MASt3R for feature matching, GLOMAP for global optimization, and FC-CLIP for semantic segmentation.
The framework successfully generates semantically-labeled 3D point clouds, 2D bird's-eye-view maps, and 3D bounding boxes, providing comprehensive spatial understanding for mobile robot navigation and scene analysis. This work represents a significant advancement in bridging the gap between robotic perception and 3D scene understanding, with immediate applications in autonomous cleaning robots, indoor navigation, and spatial AI systems.